Wikipedia content analysis
As part of trying to make Wikipedia faster we performed an analysis on a sample of content to see how we could improve what was served and maybe lazy load some part of it.
This was an iterative process of gathering reports, interpreting them and visualizing them.
The repo features a command line tool for fetching HTML dumps from benchmark endpoints that perform transformations (loot) on the content, and stores the files, gzips them, and produces summarized data for the report visualization tool to show.
It also features a webapp that visualizes such reports to help interpret the data and drive the research (live version)
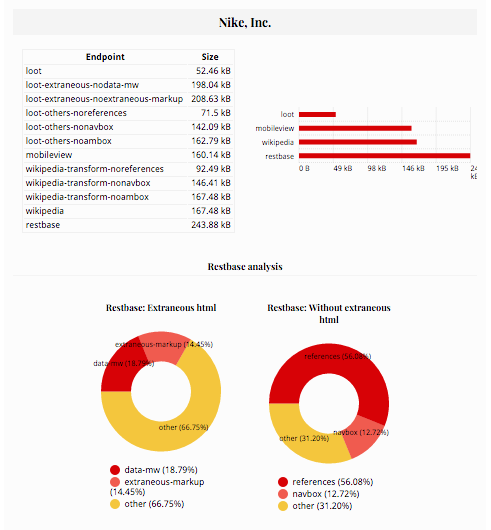
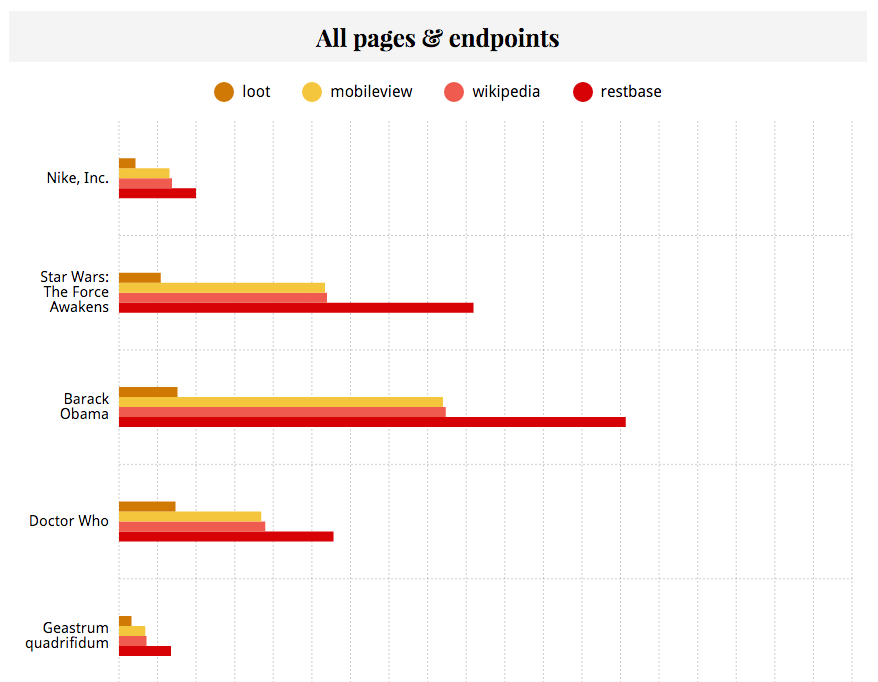
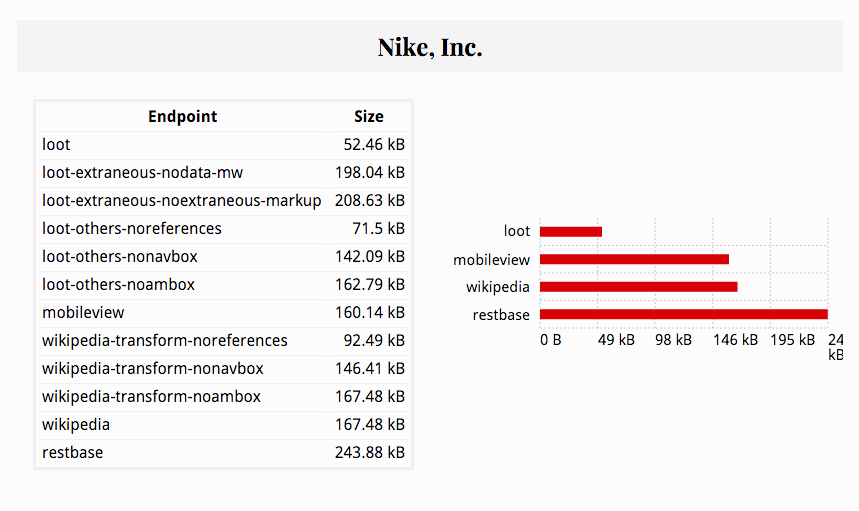
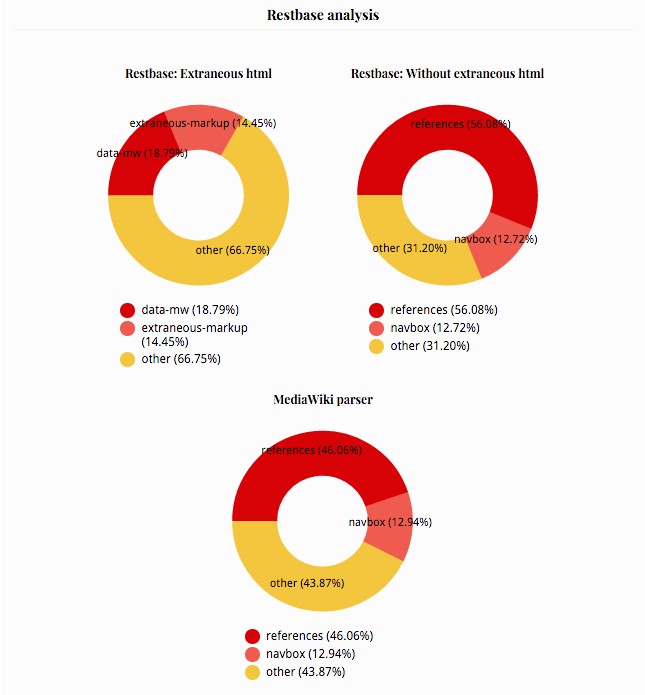
In the report you can see a comparison of the selected pages from different endpoints and their sizes, and then a per-page report showing more detailed data about what the html content is composed of.